
글로벌 빅테크들이 주도하는 AI 전쟁 속에서 반가운 소식이 들려왔습니다. 바로 통신 대기업 KT가 한국의 문화와 데이터를 듬뿍 담아 자체 개발한 거대언어모델(LLM), '믿:음(midm)'을 오픈소스로 공개한 것이죠! 🚀 개발자 커뮤니티는 그야말로 축제 분위기입니다. 이제 우리도 한국어에 '진심인' AI를 마음껏 연구하고 상업적으로 활용할 길까지 열렸으니까요. 이 글에서는 KT의 믿음이 대체 뭐길래 이렇게 화제인지, 모델별 특징은 무엇이고 어떻게 다운로드해서 쓸 수 있는지 A부터 Z까지 속 시원하게 파헤쳐 보겠습니다.
KT 믿:음(midm), 너 정체가 뭐니? 🤔
'믿음'은 KT가 처음부터 끝까지 자체 기술력으로, 오직 한국어와 한국 문화를 위해 개발한 토종 거대언어모델(LLM)입니다. 단순히 영어를 번역하는 수준을 넘어, 우리나라의 역사, 법, 금융 지식은 물론이고 '아 다르고 어 다른' 미묘한 뉘앙스나 속담, 경어체까지 제대로 이해하도록 설계되었죠. KT는 법적으로나 윤리적으로 문제가 없는 고품질의 우리말 데이터를 대규모로 확보하고, 6단계 이상의 깐깐한 필터링을 거쳐 모델을 학습시켰다고 해요. 그야말로 'K-정신'이 투철한 AI라고 할 수 있겠네요!
"KT가 지향하는 '한국적 AI'는 단순히 한국어를 처리하는 것을 넘어, 한국의 정신(Value), 방식(Style), 지식(Knowledge)을 깊이 있게 학습하여, 국내 이용자의 맥락과 언어 표현을 가장 잘 이해하고 응답할 수 있는 AI를 의미합니다." – KT AI 공식 소개 자료 中
골라 쓰는 재미! 믿:음 2.0 모델 라인업 🔎
KT는 2025년 7월, 한층 더 강력해진 '믿음 2.0'을 공개하며 개발자들을 위해 두 가지 버전을 오픈소스로 풀었습니다. 사용 목적과 환경에 따라 최적의 모델을 선택할 수 있도록 한 KT의 배려가 돋보이는 부분입니다.
- 믿음 2.0 Mini (2.3B): 작고 가벼워 온디바이스(On-device) AI 구현에 최적화된 모델입니다. 스마트폰이나 소형 기기에서 사용자의 의도를 파악하거나 번역 같은 특정 기능을 수행하는 데 안성맞춤이죠.
- 믿음 2.0 Base (11.5B): 성능과 효율 사이에서 절묘한 균형을 맞춘 범용 모델입니다. 웬만한 AI 서비스 개발에는 이 모델만으로도 충분한 성능을 기대할 수 있습니다. 놀라운 점은 국내 독자 모델 중 10B(100억) 파라미터 이상 규모를 상업적 용도로까지 공개한 최초의 사례라는 것입니다!
- 믿음 2.0 Pro (41B): 이름처럼 전문가를 위한 고성능 모델입니다. 현재는 비공개 테스트(In private preview) 중이지만, 앞으로 공개된다면 더욱 복잡하고 정교한 작업이 가능해질 것으로 기대됩니다.
핵심 포인트
KT '믿음'은 한국어와 한국 문화에 특화된 국산 LLM입니다. 특히 Base (11.5B) 모델은 상업적 이용까지 가능한 오픈소스로 공개되어, 국내 개발자들에게 새로운 기회의 문을 열었습니다.
개발자 필독! 믿:음 LLM 다운로드 방법 (Hugging Face)
자, 이제 가장 중요한 부분입니다. 이 강력한 AI 모델을 어떻게 내 컴퓨터로 데려올 수 있을까요? 방법은 의외로 간단합니다. 바로 AI 개발자들의 성지, '허깅페이스(Hugging Face)'를 이용하는 것이죠. 아래 단계를 차근차근 따라 해보세요.
1. 사전 준비: Git LFS 설치
LLM 모델 파일은 크기가 매우 크기 때문에, 대용량 파일을 위한 Git 확장 프로그램인 'Git LFS(Large File Storage)'를 먼저 설치해야 합니다. 터미널이나 커맨드 프롬프트에서 아래 명령어를 입력하세요.
# macOS (Homebrew 사용 시)
brew install git-lfs
# 설치 후 LFS 활성화 (필수!)
git lfs install2. 허깅페이스에서 모델 다운로드
KT는 공식적으로 허깅페이스 컬렉션을 통해 모델을 제공합니다. 원하는 모델 (예: Base Instruct 모델) 페이지로 이동한 뒤, 저장소 주소를 복사하여 터미널에 `git clone` 명령어를 실행하면 됩니다.
# 예시: Midm-2.0-Base-Instruct 모델 다운로드
git clone https://huggingface.co/K-intelligence/Midm-2.0-Base-Instruct이제 여러분의 로컬 환경에서도 KT의 '믿음' LLM을 활용한 개발을 시작할 수 있습니다. 간단한 파이썬 코드로 모델을 불러와 테스트해보는 것도 좋은 시작이 될 겁니다. 😉
왜 '믿:음'을 주목해야 할까?
단순히 '국산'이라는 타이틀 때문만은 아닙니다. '믿음'은 여러 면에서 개발자들에게 매력적인 선택지가 될 수 있습니다.
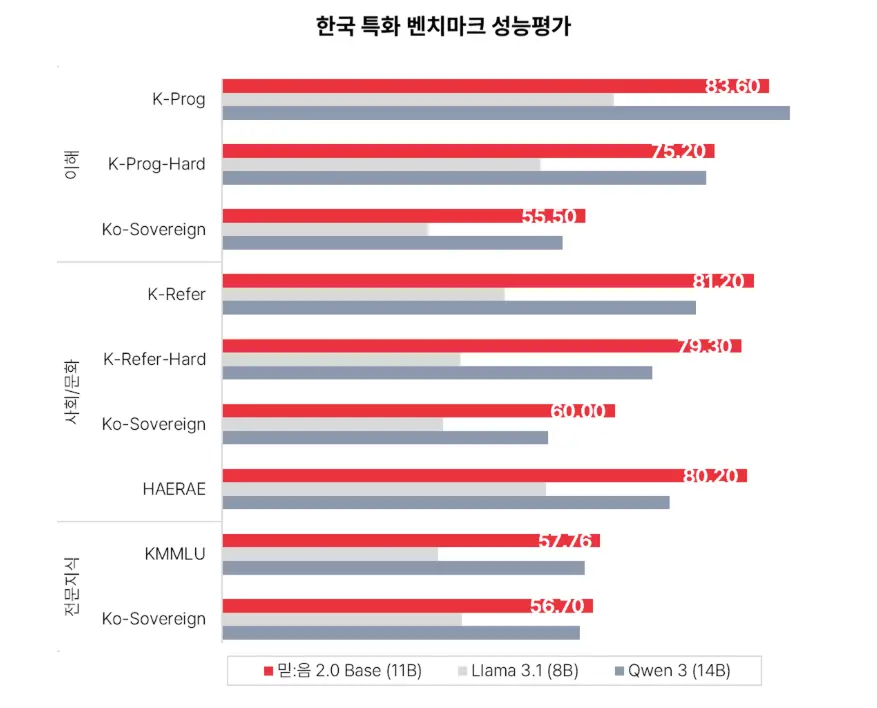
- 압도적인 한국어 성능: 자체적으로 구축한 한국 특화 벤치마크에서 글로벌 SOTA(최고 수준) 모델을 능가하는 성능을 보여줬습니다. 더 이상 어색한 번역투 답변은 안녕!
- 신뢰와 안전: KT는 개발 초기부터 '책임감 있는 AI(Responsible AI)' 원칙을 적용했습니다. 유해 정보를 효과적으로 제어하고, 악의적인 프롬프트 공격에 대한 방어력(강건성)도 GPT-4o 수준으로 확보했다고 하니, 안심하고 서비스를 만들 수 있겠죠.
- 상업적 활용 가능: MIT 라이선스로 배포되어 누구나 자유롭게 연구하고, 상업적인 제품이나 서비스를 만드는 데 활용할 수 있습니다. 이는 국내 AI 스타트업과 개발자들에게 엄청난 기회입니다.
마무리: 한국 AI 생태계의 새로운 가능성
KT의 '믿음' LLM 공개는 단순한 모델 발표를 넘어, 한국 AI 생태계 전체에 활력을 불어넣는 중요한 사건입니다. 이제 우리 개발자들도 한국인의 생각과 말을 가장 잘 이해하는 강력한 도구를 손에 쥐게 되었습니다. 이 '믿음'직한 AI를 가지고 또 어떤 혁신적인 서비스들이 탄생하게 될지, 벌써부터 가슴이 뜁니다. 여러분도 지금 바로 '믿음'을 다운로드하여 새로운 가능성을 탐험해 보시는 건 어떨까요?